

Entity Framework Core (EF Core) offers developers two powerful querying strategies: Single and Split Queries. In this article, we’ll delve into the pros and cons of each, helping us make informed decisions for efficient data retrieval.
The sample in our repository provides EF Core migrations to create a relational database whose schema illustrates a simple hierarchical structure. We establish relationships between tables through foreign key constraints, ensuring data integrity and allowing for efficient retrieval of related information. With this database, we will demonstrate what single and split queries are.
Understanding Single Queries
The Single Query approach in EF Core is about getting all the needed data in one go. It’s like eagerly grabbing everything we need in a single database query.
This approach reduces the number of round trips between our application and the database. It is beneficial when dealing with complex data models or fetching related data (e.g., data from multiple tables with relationships).
In EF Core, we can use Eager Loading, done with the Include method, to specify the related entities to be included in the query:
var companies = _dbContext.Companies
.Include(company => company.Departments)
.ToList();
It’s not difficult to find out what SQL query EF Core produces to fetch data from our database using, for example, ToQueryString() or database profilers:
SELECT [c].[Id], [c].[Name], [d].[Id], [d].[CompanyId], [d].[Name] FROM [Companies] AS [c] LEFT JOIN [Department] AS [d] ON [c].[Id] = [d].[CompanyId] ORDER BY [c].[Id]
This query returns a set of rows, each containing columns from both the Companies and Departments tables. It means we don’t have to perform multiple queries to retrieve all the necessary data.
Simultaneously, we may notice that a company’s properties are duplicated multiple times for each of its departments:
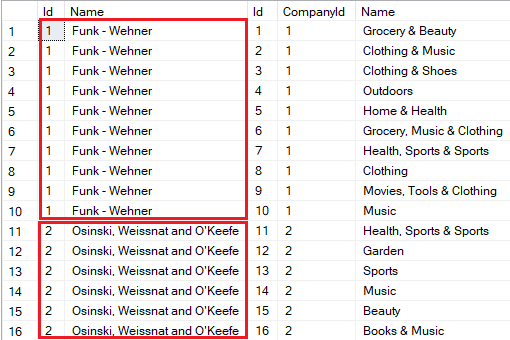
Typically, redundant data doesn’t significantly impact application performance.
But it’s easy to guess what will happen if we include more types of same-level related data to be retrieved along with the main Company entity. Now imagine what will happen if the Company contains, for example, a huge binary property to store a logo image. As we include more types the database server will transfer more redundant data to the client application over the network.
Let’s update the previous query to also include the products that the company produces:
var companies = _dbContext.Companies
.Include(company => company.Departments)
.Include(company => company.Products)
.ToList();
Examining the underlying query and its output, we notice that the number of rows in the result set has grown exponentially:
SELECT [c].[Id], [c].[Name], [d].[Id], [d].[CompanyId], [d].[Name], [p].[Id], [p].[CompanyId], [p].[Name] FROM [Companies] AS [c] LEFT JOIN [Department] AS [d] ON [c].[Id] = [d].[CompanyId] LEFT JOIN [Product] AS [p] ON [c].[Id] = [p].[CompanyId] ORDER BY [c].[Id], [d].[Id]
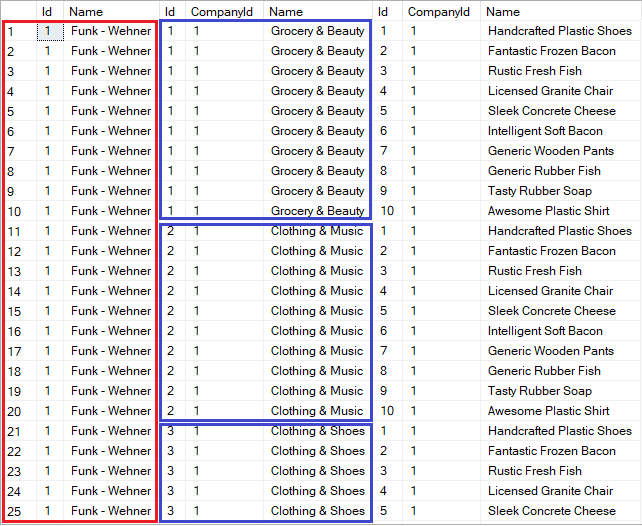
Now, not only companies are duplicated (marked in red). Departments start duplicating as well (marked in blue). This effect is called cartesian explosion.
So, while single querying can boost performance, we must be careful. Fetching too much data in one go might slow things down. Fortunately, EF Core can recognize this situation, and generate a corresponding warning message:
warn: Microsoft.EntityFrameworkCore.Query[20504] Compiling a query which loads related collections for more than one collection navigation, either via 'Include' or through projection, but no 'QuerySplittingBehavior' has been configured. By default, Entity Framework will use 'QuerySplittingBehavior.SingleQuery', which can potentially result in slow query performance. See https://go.microsoft.com/fwlink/?linkid=2134277 for more information. To identify the query that's triggering this warning call 'ConfigureWarnings(w => w.Throw(RelationalEventId.MultipleCollectionIncludeWarning))'.
If we encounter this message while developing our application, we should think about leveraging split queries.
Understanding Split Queries
Unlike the all-in-one nature of single querying, Split Queries break down data retrieval into smaller steps. This approach is handy when we want to fetch only the necessary data, avoiding over-fetching and optimizing for specific use cases.
In EF Core, incorporating split querying involves using the AsSplitQuery() method. This method signals to EF Core that it should split queries, enabling data retrieval optimization:
var companies = _dbContext.Companies
.Include(company => company.Departments)
.AsSplitQuery()
.ToList();
As a result, EF Core will produce two separate SQL queries:
SELECT [c].[Id], [c].[Name] FROM [Companies] AS [c] ORDER BY [c].[Id] SELECT [d].[Id], [d].[CompanyId], [d].[Name], [c].[Id] FROM [Companies] AS [c] INNER JOIN [Department] AS [d] ON [c].[Id] = [d].[CompanyId] ORDER BY [c].[Id]
These queries will return two separate result sets:
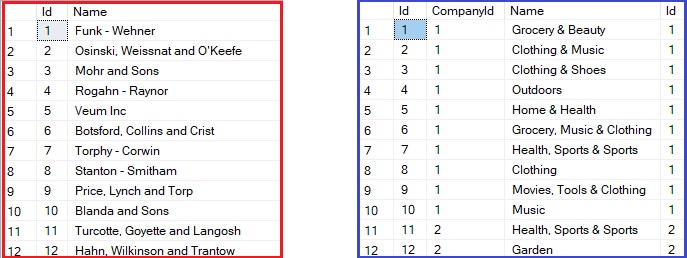
As we can see, the first query (in red) retrieves all the necessary companies. The second query (in blue), in turn, retrieves their departments. Now, EF Core can combine the results of these queries into a collection of Company objects with departments.
The good news is that neither of the result sets contains data duplicates. That in turn means that the volume of data the database server transfers to our app is lower than in the case of single querying.
At the same time, we need to perform two SQL queries instead of a single one. More queries may result in additional round-trips between the application and the database.
Besides, let’s imagine that before performing the second query, one of the companies returned in the first result set had been deleted from the database along with its departments. Naturally, the second result set won’t contain departments of the deleted company. As a result, the user of our app may operate with inconsistent resulting data.
So, if our database can be updated concurrently, we need to consider using serializable or snapshot transactions to prevent such situations. Keep in mind that transactions come with overhead and can impact performance, especially if they involve locking resources.
Use Split Queries by Default
EF Core uses the single querying strategy by default. However, we can configure EF Core to use split querying mode as the default:
protected override void OnConfiguring(DbContextOptionsBuilder optionsBuilder)
{
optionsBuilder.UseSqlServer(
"Server=(localdb)\\MSSQLLocalDB;Integrated Security=true;Initial Catalog=SingleAndSplitQueriesInEFCore",
options => options.UseQuerySplittingBehavior(QuerySplittingBehavior.SplitQuery));
}
Although this example configures EF Core DbContext using SQL Server as the database provider, we can enable query splitting behavior for other database providers as well.
Now, to perform specific queries in single querying mode, we have to use the AsSingleQuery() method:
var companies = _dbContext.Companies
.Include(company => company.Departments)
.AsSingleQuery()
.ToList();
A Performance Comparison
Our sample code provides a benchmark, enabling us to measure and compare the performance of single and split queries:
| Method | Mean | Error | Median | Allocated | |------------------------------------------------------- |----------:|---------:|----------:|----------:| | GetCompaniesWithDepartmentsUsingSingleQuery | 16.64 ms | 0.078 ms | 16.62 ms | 4.04 MB | | GetCompaniesWithDepartmentsAndProductsUsingSingleQuery | 200.60 ms | 1.786 ms | 198.98 ms | 46.93 MB | | GetCompaniesWithDepartmentsUsingSplitQuery | 18.97 ms | 0.245 ms | 18.73 ms | 4.25 MB | | GetCompaniesWithDepartmentsAndProductsUsingSplitQuery | 35.62 ms | 0.403 ms | 35.39 ms | 8.35 MB |
According to the benchmark result, AsSingleQuery() exhibited slightly faster execution times compared to AsSplitQuery() while fetching companies without products (16.64 ms vs. 18.97 ms). Memory consumption was lower with AsSingleQuery() as well (4.04 MB vs. 4.25 MB).
However, when single querying leads to the cartesian explosion effect, we see very different results. Now AsSingleQuery() gets much slower in comparison with AsSplitQuery() (200.60 ms vs. 35.62 ms) and requires much more memory (46.93 MB vs. 8.35 MB), retrieving all data with duplication in one go.
We must remember, however, that benchmark results will vary based on factors such as database size, query complexity, network latency, and hardware configuration.
Conclusion
In summary, single querying can be more efficient in scenarios where we need a lot of related data at once. On the other hand, split querying might be beneficial when we want to optimize for specific use cases or reduce the amount of data fetched at a given time.
Both strategies come with trade-offs. Single querying might bring in too much data if we’re not careful, and split querying means more trips to the database.
Deciding between single and split queries is about finding the right balance that fits the needs of our application. If we often need a large set of connected data, we should opt for the single query approach. If we need to be picky and precise, split querying is our friend.
