

In this article, we are going to look at one of the key challenges with building microservices: resilience. We will look at why the problem exists, and how the .NET library Polly can help us provide a solution to this problem, enabling resilient microservices.
So, let’s dive in.
Why Do We Need to Build Resilient Microservices?
Before we start adding resilient microservices, it’s worth spending a moment understanding what resiliency is.
What Is Resiliency?
“Resiliency” in the context of software can be described as the ability to maintain acceptable availability for the services it provides, dealing with any issue that may arise in doing so.
For example, if we were to build an API that our customers could consume, we might include in our agreement an SLA (service level agreement) ensuring a certain uptime (e.g 99.9%). In order to maintain this SLA, we need to ensure our service stays ‘up’, or be ‘resilient’.
To build ‘resilient microservices’, we need to ensure our software can deal with issues such as:
- Increased load
- Security issues
- Network failures
- Dependency failures
In this article, we will be mainly dealing with the last two, being dependency failures caused by the network.
How Can We Be Resilient?
In a previous article, we created an API Gateway to encapsulate a few microservices. Since the consumers only deal with the API Gateway, it means any downstream microservice failure (aka a ‘dependency failure’, in this case), would affect the API Gateway’s ability to service those requests, thus affecting uptime.
In order for our API Gateway to be resilient, we need to be proactive in dealing with these issues. That means, understanding that these issues can and will happen, and having a well-thought-out strategy to deal with them. That could be, but not limited to: returning a previously cached result, falling back to another piece of logic, or erroring “quickly” to not tie up resources that can affect other functionality.
This is where the .NET library Polly can help us.
How Polly Helps Build Resilient Microservices
Polly is a library that helps us build resilient microservices in .NET. It allows us to specify a set of ‘policies’ that dictate how our app should respond to various failures. A simple example could be: if a SQL timeout occurs, then “do something” (for example, try again N times). We could of course do this manually, but that would result in a lot of boilerplate and duplicated code, where Polly can do it for us in a much more graceful pattern.
In our case, we will leverage Polly to add resilient features to the API Gateway we built in the previous article so that any microservice failure can be handled properly.
Revisiting Our API Gateway and Microservices
In our previous article, we built the following architecture:
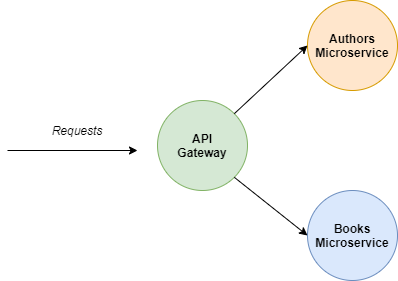
Requests would flow into the API Gateway, and be directed to either the Authors or Books microservice, depending on the URL.
We are now going to expand upon this example and add some resiliency features. If you’d like to download the starter project and follow along, head over to our repository.
Simulating a Dependency Failure
In a real-world scenario, the Authors and Books microservice would serve data from a remote place, for example, a SQL Server database or a file on Azure / S3 storage. In our case, they are simply returning data from in-memory collections.
However, to ‘simulate’ a network & dependency failure, we can simply “stop” the authors and books microservices, which will result in the API Gateway returning errors.
To prove that, let’s go ahead and run all three services, and confirm both URLs are working by using our consumer.html page.
First, let’s hit the Get Books button:

Next, the Get Authors button:
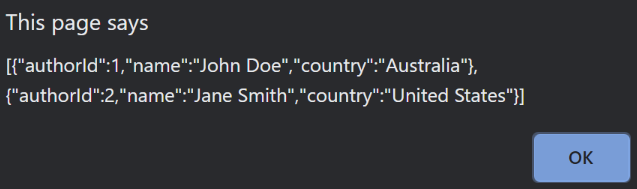
Both our microservices are working, and the API Gateway is in turn responding as expected.
Now, let’s stop both the Books and Authors microservices by stopping the Kestrel process.
If we hit the buttons now, we see a brief pause of a few seconds, then the following error:
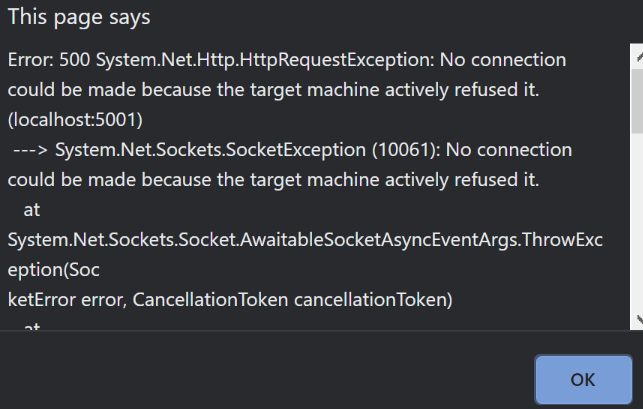
We have just simulated a dependency and network failure! This exact situation can and will happen when we run these apps in production, for example:
- The network could blip, as a result of infrastructure upgrades
- The microservice host machine could experience downtime due to a poor deployment strategy, or host upgrades
This is just one example of a failure. There are other reasons that errors could happen, but the point is we can’t control how a downstream dependency could behave, but we can control how we (in this case, the API Gateway) can deal with it.
Using Polly to Build Resilient Microservices
Let’s now introduce Polly to our API Gateway.
Creating a “Fallback” Policy
The easiest way to do this is via the NuGet package manager console:
PM> install-package Polly
The first and most simple way to handle failures with Polly is to capture any Exception, and handle them accordingly. This is called the Fallback strategy.
First, let’s open up ProxyController.cs in the API Gateway, and add the following using statements:
using Polly; using Polly.CircuitBreaker; using Polly.Fallback; using Polly.Retry; using Polly.Wrap;
Let’s then declare a local variable for our Policy:
private readonly AsyncFallbackPolicy<IActionResult> _fallbackPolicy;
There are many ways to instantiate and store policies, such as using registries and wiring them up via Startup. However since this article is an introduction piece into Polly, we’ll keep it simple and create it in our class.
Next, let’s modify our constructor:
public ProxyController(IHttpClientFactory httpClientFactory)
{
_fallbackPolicy = Policy<IActionResult>
.Handle<Exception>()
.FallbackAsync(Content("Sorry, we are currently experiencing issues. Please try again later"));
_httpClient = httpClientFactory.CreateClient();
}
The nice thing about Polly is that the API’s are very fluent and human-readable. The above can be translated to: “I want to create a Policy for things that return IActionResult. When an Exception occurs, I want to handle it and fallback to returning a friendly message”.
Let’s now modify our ProxyTo method, to make use of our new policy:
private async Task<IActionResult> ProxyTo(string url)
=> await _fallbackPolicy.ExecuteAsync(async () => Content(await _httpClient.GetStringAsync(url)));
Very simply, we are wrapping our existing code with the call to ExecuteAsync on our policy.
Let’s now see what happens when we hit either the Get Books or Get Authors button:
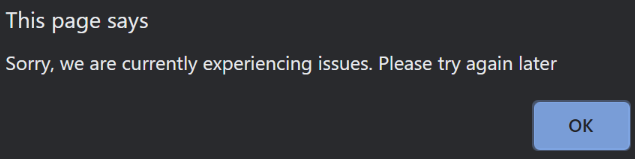
Great! No matter what happens to our downstream microservices, we can now gracefully handle the error and show something more readable to our consumers.
Creating a “Retry” Policy
Often in distributed applications, transient errors can occur (network blip, for example). These errors might only exist for a moment, then go away. Without any special code, normal requests would error as soon as the first error occurred. However, we can use the Retry policy in Polly to proactively expect and handle this error.
It could be difficult to reproduce a network failure, so to simulate this scenario, let’s modify our Authors service to fail on the first request, then succeed on the second.
To do this, let’s open up Repository.cs and add a private member:
private bool _shouldFail = true;
Next, let’s modify the GetAuthors() method:
public IEnumerable<Author> GetAuthors()
{
if (_shouldFail)
{
_shouldFail = false;
throw new System.Exception("Oops!");
}
return _authors;
}
What we are doing is simply failing the first time, then succeeding the times after that.
Let’s build and run the Authors microservice, and see what happens if we hit the Get Authors button:
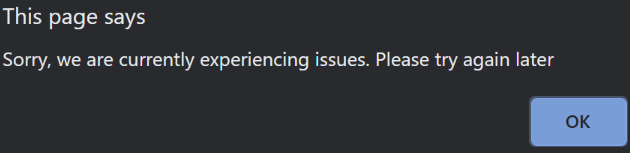
Then let’s hit the button again:
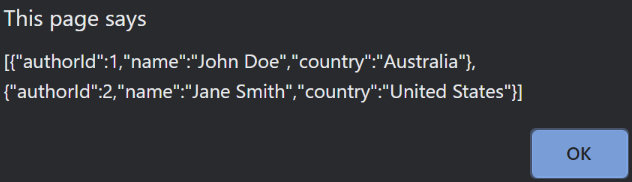
So the first request could have potentially succeeded if we “retried” again. That said, let’s stop all our applications, and go ahead and do that.
Let’s head back to ProxyController in our API Gateway, and add a new policy:
private readonly AsyncRetryPolicy<IActionResult> _retryPolicy;
Then modify our constructor:
public ProxyController(IHttpClientFactory httpClientFactory)
{
...
_retryPolicy = Policy<IActionResult>
.Handle<Exception>()
.RetryAsync();
...
}
Similar to our existing policy, here we are handling any exception on things that return IActionResult, and this time calling RetryAsync. This means, “retry once”. We can also specify how many times we’d like to retry:
.RetryAsync(2)
However, for our purposes, let’s leave things as the default retry behavior of once.
Let’s then modify our ProxyTo method:
private async Task<IActionResult> ProxyTo(string url)
=> await _retryPolicy.ExecuteAsync(async () => Content(await _httpClient.GetStringAsync(url)));
Now let’s see what happens if we build and run all applications, and hit the GetAuthors button:
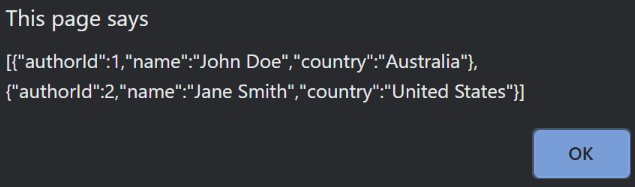
We can see the request succeeded the first time. Unbeknownst to the user, it initially failed but thanks to Polly our application is now “resilient” to this failure, by means of a simple retry.
Creating a “Circuit Breaker” Policy
Next, let’s look at another resiliency pattern called Circuit Breaker. As the name suggests, this pattern is all about creating a “breaker” so that we don’t keep failing unnecessarily. For example, if a downstream system was timing out, it’s potentially under load, so why keep slamming it? We can give it a break for a while, then try again later.
To simulate this behavior, let’s again go back to our Authors repository, and make some adjustments.
First, let’s add a private member:
private DateTime _startTime = DateTime.UtcNow;
Then let’s modify GetAuthors():
public IEnumerable<Author> GetAuthors()
{
if (_shouldFail)
{
_shouldFail = false;
throw new Exception("Oops!");
}
if (_startTime.AddMinutes(1) > DateTime.UtcNow)
{
Thread.Sleep(5000);
throw new Exception("Timeout!");
}
return _authors;
}
What we are doing now in addition to our previous behavior, is throwing a timeout exception for the first minute of the microservice lifetime.
Let’s build and run all our applications again, then hit the Get Authors button again:
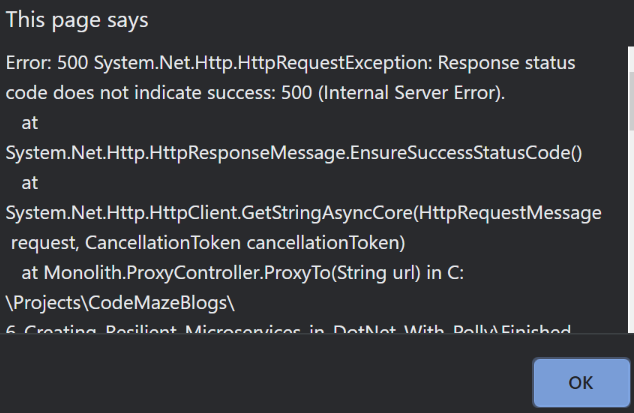
Remember we are still using the Retry policy, and we still have the “should fail on first request” behavior.
So let’s see what’s happening behind the scenes:
- Polly is calling our Authors microservice
- The Authors service is failing, because it’s the first request
- Polly is calling the Authors microservice again (because of the “Retry” policy)
- The Authors service is waiting for 5 seconds then failing because of a timeout
We can hit the button again and again, and the same behavior above will occur, until finally after a minute, we then see the request succeeds:
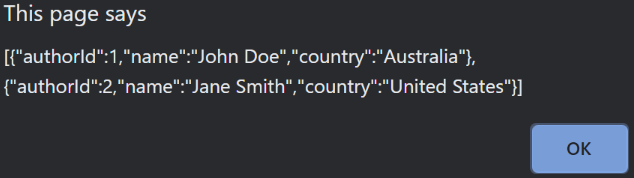
This behavior causes the following problems:
- Continuous pressure on the Authors service
- Resources on the API Gateway are being wasted
- Excessive network bandwidth
- Taking too long to fail
To solve these problems, let’s introduce a circuit breaker.
Adding the circuit breaker
First, let’s add another policy to our ProxyController:
private static AsyncCircuitBreakerPolicy _circuitBreakerPolicy;
It’s worth noting this is a little different from how we declare our other policies, in that we are using a static access modifier. The reason for this is circuit breaker relies on a shared state, to track failures across requests. By default, a .NET 5 controller class is instantiated on every request, so we need to implement a custom singleton. A better approach here would be to include our code in a service and use the Dependency Injection container built into .NET to mark it as a singleton. However, this will work fine for demonstration purposes.
With that in mind, let’s modify our constructor:
public ProxyController(IHttpClientFactory httpClientFactory)
{
...
if (_circuitBreakerPolicy == null)
{
_circuitBreakerPolicy = Policy
.Handle<Exception>()
.CircuitBreakerAsync(2, TimeSpan.FromMinutes(1));
}
...
}
Let’s again modify our ProxyTo method:
private async Task<IActionResult> ProxyTo(string url)
=> await _circuitBreakerPolicy.ExecuteAsync(async () => Content(await _httpClient.GetStringAsync(url)));
Let’s build and run all our applications again, and see what happens when we hit the Get Authors button:
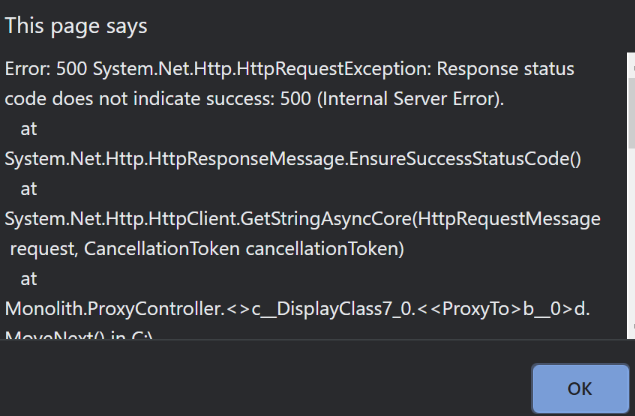
We immediately get a 500 error, which is the “fail first-time” behavior we implemented in our Authors repository. This is error one.
If we hit it again, we get a short delay of a few seconds, and the same error again. This is the “timeout” behavior occurring. This is error two.
If we hit it a third time, we now fail quickly and get this error:
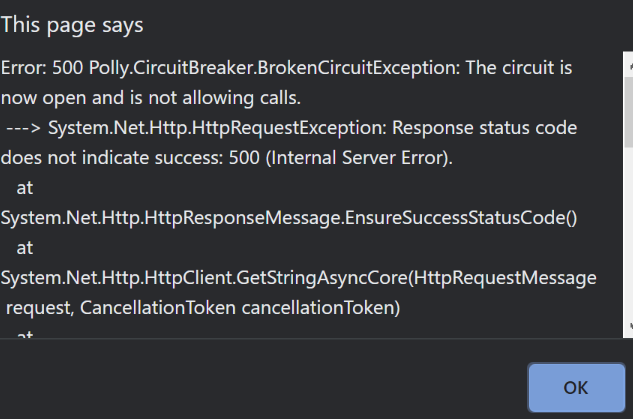
Notice this time the message includes BrokenCircuitException. This confirms the circuit is “open”, and Polly won’t try to perform the action for a total of 1 minute, saving precious resources and “failing fast”, which as we mentioned earlier is a great principle in building resilient microservices.
If we wait a minute, we’ll then see the normal successful response, signifying the circuit is “closed” and normal behavior continues.
Combining Our Policies
So far, in each example, we’ve dealt with one particular issue and handled them in one way. However true resilience means dealing with a variety of scenarios and handling them in different ways. To accomplish this, we can combine our policies.
To do that, let’s add a new policy to our class:
private readonly AsyncPolicyWrap<IActionResult> _policy;
Then update our constructor:
public ProxyController(IHttpClientFactory httpClientFactory)
{
...
_policy = Policy<IActionResult>
.Handle<Exception>()
.FallbackAsync(Content("Sorry, we are currently experiencing issues. Please try again later"))
.WrapAsync(_retryPolicy)
.WrapAsync(_circuitBreakerPolicy);
...
}
This time, we declare a fallback policy (same as previous), then wrap that with our retry policy, then wrap that with a circuit breaker. Effectively we are saying: retry once, fallback to what we specify, and open a circuit for 1 minute if 2 errors occur.
Let’s again modify our ProxyTo method:
private async Task<IActionResult> ProxyTo(string url)
=> await _policy.ExecuteAsync(async () => Content(await _httpClient.GetStringAsync(url)));
If we build and run all our apps again, we see the following behavior each time we press Get Authors:
- A brief pause, then the fallback error returned (behind the scenes, we actually retried once)
- Immediately getting the same fallback error (the circuit is now “open”)
Subsequent clicks will get the same behavior as 2 until 1-minute passes and normal behavior resumes.
This is extremely powerful as we are:
- Retrying to deal with intermittent failures (retry)
- Not wasting resources (circuit breaker)
- Showing something to the user (fallback)
Conclusion
There are a number of other features that exist in Polly to help build resilient microservices, and we have only touched on a few common ones.
We all know that when we move from a single, in-process application to a set of microservices, a number of challenges come with it. Even though our application isn’t doing anything meaningful, with a bit of imagination it’s easy to see how real problems can occur and how Polly can help us deal with these problems.
In this article, we have shown how Polly can help prepare us for these inevitable problems, and therefore increase our resiliency, which in turn increases uptime, saves resources, and improves customer satisfaction.
Happy coding!
