

Updated on
In this article, we are going to learn some useful C# tips on how to improve our code quality and performance.
Let’s get started!
Why These C# Tips?
Before we begin, let us briefly discuss why we chose these specific C# tips over many others that certainly exist. With these tips, we can achieve a good balance of code quality and performance improvements. Note that some of these are only available with newer versions of C#, and we will state explicitly when that is the case.
Also, these C# tips are relatively easy to integrate into an existing codebase. You will be able to apply these tips and reap the benefits, as soon as you are done reading this article.
Whenever we write code, we are very likely to encounter:
- Guarding against null values
- If-else statements
- Exception handling
- Data Transfer Objects
- Collections
So let us see how we can improve all of these in our code!
The Proper Way to Do a Null Checks
We perform null-checks quite often in our code, to guard against the dreaded NullReferenceException. The most common way we do this is:
var product = GetProduct();
if (product == null)
{
// Do something if the object is null.
}
Do you know what the problem is with this approach? The == operator can be overridden and there is no strict guarantee that comparing an object with null will produce the result that we expect. Luckily, there is a new operator that is introduced in C# version 7, the is operator.
Here is how we can perform a null-check with the new is operator:
var product = GetProduct();
if (product is null)
{
// Do something if the object is null.
}
The is operator will always evaluate to true if the specified object instance is null. It is also a cleaner way of writing null-checks because it reads like a sentence.
Beginning with C# 9, you can use a negation pattern to do a null-check:
var product = GetProduct();
if (product is not null)
{
// Do something if the object is not null.
}
The same applies to this type of check, it will only evaluate to true if the specified object is not null. It can not be overridden.
C# Tips to Reduce Nesting in Your Code
Nesting is when we have code between two curly braces. One simple example of nesting is the body of a method. We see that this is a natural occurrence in the language. However, we can face some problems when we have multiple levels of nesting.
Why is code nesting a problem? Usually, one or two levels of nesting are not problematic. But, the more levels of nesting we have, the harder it becomes to read the code, and bugs will become harder to catch.
Luckily, we can fix this easily. We are going to give you a few C# tips for reducing nesting in our code.
Let us look at an example where we have an if-else statement. Inside the if-statement we are returning some value:
Product PurchaseProduct(int id)
{
var product = GetProduct(id);
if (product.Quantity > 0)
{
product.Quantity--;
return product;
}
else
{
SendOutOfStockNotification(product);
return null;
}
}
In cases like these, the entire else statement can be removed, and we are effectively reducing the nesting level for that part of the code:
Product PurchaseProduct(int id)
{
var product = GetProduct(id);
if (product.Quantity > 0)
{
product.Quantity--;
return product;
}
SendOutOfStockNotification(product);
return null;
}
Sometimes, we need to make sure that a couple of conditions are met before we perform some operation. This usually results in multiple levels of nesting and code that is harder to read:
bool IsProductInStock(int id)
{
var product = GetProduct(id);
if (product is not null)
{
if (product.Quantity > 0)
{
return true;
}
}
return false;
}
We can fix this by applying the “early return” principle:
bool IsProductInStock(int id)
{
var product = GetProduct(id);
if (product is null)
{
return false;
}
if (product.Quantity <= 0)
{
return false;
}
return true;
}
The early return principle states that we should return from a method as soon as possible. In our case, we first check if the product is null, and return false if it is. Then we check if the quantity is less than or equal to zero, and return false if it is. Otherwise, the product is not null and the quantity is greater than zero, so we return true.
We can optimize this further by joining the two if-statements into a single one:
bool IsProductInStock(int id)
{
var product = GetProduct(id);
if (product is null || product.Quantity <= 0)
{
return false;
}
return true;
}
Introducing Using Declarations
Using statements in the past always assumed an additional level of nesting in our code that was not necessary:
using (var streamReader = new StreamReader("..."))
{
string content = streamReader.ReadToEnd();
}
Starting with C# 8, we can remove the curly braces from the using statements in our code:
using var streamReader = new StreamReader("...");
string content = streamReader.ReadToEnd();
It is important to note that when using this feature, the using statement has block-level scope.
Improve Logical Expression Readability
C# 9 introduced a set of new logical patterns that we can use to improve the readability of our logical expressions. Let us see how we can use them in our code!
We are going to write a function to check if a specified character is a letter:
bool IsLetter(char ch) => (ch >= 'a' && ch <= 'z') || (ch >= 'A' && ch <= 'Z');
This is the typical approach we would take, although it is a little cumbersome to write because we have to repeat the character parameter for every check.
With the new and and or logical pattern combinators, we can rewrite the previous function:
bool IsLetter(char ch) => ch is (>= 'a' and <= 'z') or (>= 'A' and <= 'Z');
This new version is much more readable because it almost reads like a sentence. We also do not need to specify the character parameter more than once.
Remove If-Else Statements for Setting Boolean Values
We often encounter a situation in our code where we need to return a bool value from a function:
bool IsInStock(Product product)
{
if (product.Quantity > 0)
{
return true;
}
else
{
return false;
}
}
Although this approach is mostly fine, we have to ask ourselves if we even need an if-statement in the first place. Since we already have a logical expression inside the if-statement, we can simplify the method by simply returning the value of that logical expression:
bool IsInStock(Product product)
{
return product.Quantity > 0;
}
We have to write far less code to achieve the same result, which is always desirable.
We can further simplify the previous method by using an expression body:
bool IsInStock(Product product) => product.Quantity > 0;
If we notice that the boolean expression is becoming complex, we can split it into a couple of meaningfully named local variables.
How to Simplify Switch Statements
Switch statements can be very useful when we want to evaluate some object, and based on the set of possible values return a different result.
Let’s write a switch statement to check if the current day is a weekend day or not:
switch (DateTime.Now.DayOfWeek)
{
case DayOfWeek.Monday:
return "Not Weekend";
case DayOfWeek.Tuesday:
return "Not Weekend";
case DayOfWeek.Wednesday:
return "Not Weekend";
case DayOfWeek.Thursday:
return "Not Weekend";
case DayOfWeek.Friday:
return "Not Weekend";
case DayOfWeek.Saturday:
return "Weekend";
case DayOfWeek.Sunday:
return "Weekend";
default:
throw new ArgumentOutOfRangeException();
}
As we can see, we have to write a lot of code. We can compact this further by joining all of the case statements that return the same result:
switch (DateTime.Now.DayOfWeek)
{
case DayOfWeek.Monday:
case DayOfWeek.Tuesday:
case DayOfWeek.Wednesday:
case DayOfWeek.Thursday:
case DayOfWeek.Friday:
return "Not Weekend";
case DayOfWeek.Saturday:
case DayOfWeek.Sunday:
return "Weekend";
default:
throw new ArgumentOutOfRangeException();
}
That’s a little better, wouldn’t you agree? But we can do even better than this!
Beginning with C# 8, switch expressions were introduced to help us reduce the amount of code we have to write even more.
Let’s transform the previous switch statement into a switch expression:
DateTime.Now.DayOfWeek switch
{
DayOfWeek.Monday => "Not Weekend",
DayOfWeek.Tuesday => "Not Weekend",
DayOfWeek.Wednesday => "Not Weekend",
DayOfWeek.Thursday => "Not Weekend",
DayOfWeek.Friday => "Not Weekend",
DayOfWeek.Saturday => "Weekend",
DayOfWeek.Sunday => "Weekend",
_ => throw new ArgumentOutOfRangeException()
}
As we can see, it’s much more concise and readable than before. So are we finished now? Almost.
Starting with C# 9, we can also use logical patterns in our switch expressions. The or logical pattern fits nicely with what we are trying to achieve:
DateTime.Now.DayOfWeek switch
{
DayOfWeek.Monday or DayOfWeek.Tuesday or DayOfWeek.Wednesday or DayOfWeek.Thursday or DayOfWeek.Friday => "Not Weekend",
DayOfWeek.Saturday or DayOfWeek.Sunday => "Weekend",
_ => throw new ArgumentOutOfRangeException()
}
One last optimization we can introduce is to use the negation logical pattern not:
DateTime.Now.DayOfWeek switch
{
not (DayOfWeek.Saturday or DayOfWeek.Sunday) => "Not Weekend",
DayOfWeek.Saturday or DayOfWeek.Sunday => "Weekend",
_ => throw new ArgumentOutOfRangeException()
}
The Proper Way to Rethrow Exceptions
Exception handling is a very important aspect of our code. We can often see one pattern repeated through the codebase is catching an exception, handling it locally, and then rethrowing it to a higher-level component.
The rethrowing step is where we can easily make a mistake:
try
{
await GetBlogsFromApi();
}
catch (HttpRequestException e)
{
throw e;
}
Do you know what is the problem when we rethrow an exception like this?
The stack trace of the exception gets rewritten to the line of code where we explicitly rethrow it. This means that we lose all of the valuable information about what caused the exception in the first place. This can make debugging the code very hard.
However, we can fix this very easily:
try
{
await GetBlogsFromApi();
}
catch (HttpRequestException e)
{
throw;
}
When we do it like this, the exception is rethrown while preserving the original stack trace. We are now saving all of that valuable information about what caused the exception in the first place. It will be much easier for us to debug the code, and figure out what the problem is.
How to Filter Exceptions
Do you have a situation in your code where you need to handle a specific exception multiple times? We often encounter a case like this, where we have to perform different exception handling logic based on some condition.
Let us say we want to handle an HttpRequestException in one way when the StatusCode is 400 (Bad Request), and in another way when the StatusCode is 404 (Not Found). The naive approach would be to catch the exception and then write an if-statement to check a condition:
try
{
await GetBlogsFromApi();
}
catch (HttpRequestException e)
{
if (e.StatusCode == HttpStatusCode.BadRequest)
{
HandleBadRequest(e);
}
else if (e.StatusCode == HttpStatusCode.NotFound)
{
HandleNotFound(e);
}
}
Although this works, it’s not the cleanest approach. There is a much better solution that you might not know about.
Here is how we can elegantly catch the same exception based on a certain condition:
try
{
await GetBlogsFromApi();
}
catch (HttpRequestException e) when (e.StatusCode == HttpStatusCode.BadRequest)
{
HandleBadRequest(e);
}
catch (HttpRequestException e) when (e.StatusCode == HttpStatusCode.NotFound)
{
HandleNotFound(e);
}
This approach is much cleaner and easier to extend when we need to add more conditions.
Why You Should Use Records as Data Transfer Objects
Beginning with C# version 9, the long-awaited record types feature was introduced. Records are reference types, just like classes. However, records have an amazing feature that classes don’t – they are immutable by default.
Here is how we can define a simple record:
public record ProductDto(string Id, string Name, string Category, decimal Price);
When defined like this, it is called a “Positional record”. We can also define the same record like this:
public record ProductDto
{
public string Id { get; init; }
public string Name { get; init; }
public string Category { get; init; }
public decimal Price { get; init; }
}
The new init setter allows the value of the property to be set only once when the object instance is created. After that, it can no longer be modified, thus ensuring immutability.
Positional records are a great candidate for Data Transfer Objects (DTOs) because they are immutable and very simple to define. When replacing classes with records for DTOs, you will find that the amount of code in your codebase will drastically reduce.
The Proper Way to Return Empty Collections
Often, we have methods that return a collection. We perform some validation beforehand, then populate the collection and return it. However, what should we return in case the preconditions are not met?
One option is to return null values:
IEnumerable<Product> GetProductsByCategory(string category)
{
if (string.IsNullOrWhiteSpace(category))
{
return null;
}
var products = _dbContext.Products.Where(p => p.Category == category).ToList();
return products;
}
This is generally a bad practice because we now force the calling code to check the null result.
A better approach would be to just return an empty collection:
IEnumerable<Product> GetProductsByCategory(string category)
{
if (string.IsNullOrWhiteSpace(category))
{
return new List<Product>();
}
var products = _dbContext.Products.Where(p => p.Category == category).ToList();
return products;
}
Although this approach is fine, we can achieve the same result with a cleaner approach:
IEnumerable<Product> GetProductsByCategory(string category)
{
if (string.IsNullOrWhiteSpace(category))
{
return Enumerable.Empty<Product>();
}
var products = _dbContext.Products.Where(p => p.Category == category).ToList();
return products;
}
Using Array.Empty and Enumerable.Empty is the preferred way for returning an empty collection from a method. This is because every time you instantiate an empty array or list, it is stored in memory. This increases the pressure on the Garbage Collector. However, when we use Array.Empty or Enumerable.Empty there is only one instance of an empty collection that is created, which is reusable. This will reduce the memory consumption of our application.
C# Tips to Make Your Code Robust With Readonly Collections
Let’s create a simple Writer class, with a collection of blogs:
public class Writer
{
public Writer(string name, List<Blog> blogs)
{
Name = name;
Blogs = blogs;
}
public string Name { get; set; }
public List<Blog> Blogs { get; set; }
}
What is preventing us from adding or removing blogs from the Blogs collection?
With this approach nothing. Our Writer class has no encapsulation. Someone could manipulate a Writer instance as they wish:
var writer = new Writer(“Code Maze”, new List<Blog>()); writer.Blogs.Add(blog1); writer.Blogs.Remove(blog2);
Clearly, we can’t allow this much freedom to our consumers. We will enforce encapsulation by creating a private field for storing the blogs. Let’s modify the Writer class:
public class Writer
{
private List<Blog> _blogs = new List<Blog>();
public Writer(string name, List<Blog> blogs)
{
Name = name;
_blogs = blogs;
}
public string Name { get; set; }
public List<Blog> Blogs => _blogs;
}
This implementation is a little better, but we still have the same issue as before. Nothing is preventing our consumers from manipulating the Blogs collection.
To completely close the Blogs collection from modification we can use one of the read-only collection interfaces. We can use either IReadonlyCollection or IReadonlyList. Let’s go with IReadonlyCollection and modify the Writer class:
public class Writer
{
private List<Blog> _blogs = new List<Blog>();
public Writer(string name, List<Blog> blogs)
{
Name = name;
_blogs = blogs;
}
public string Name { get; set; }
public IReadonlyCollection<Blog> Blogs => _blogs;
}
Great, we have almost completely encapsulated the Writer class.
The previous code no longer works:
var writer = new Writer(“Code Maze”, new List<Blog>()); writer.Blogs.Add(blog1); // Compiler error. writer.Blogs.Remove(blog2); // Compiler error.
This is because the IReadonlyCollection interface doesn’t contain methods for altering the collection.
However, nothing is preventing our consumers from doing this:
var writer = new Writer(“Code Maze”, new List<Blog>()); (writer.Blogs as List<Blog>).Add(blog1);
Luckily, the fix for this is simple. We will just return a new collection instance in our Writer class:
public class Writer
{
private List<Blog> _blogs = new List<Blog>();
public Writer(string name, List<Blog> blogs)
{
Name = name;
_blogs = blogs;
}
public string Name { get; set; }
public IReadonlyCollection<Blog> Blogs => _blogs.AsReadonly();
}
Now we completely encapsulate the Writer class and make our code much more robust.
Use the Memory Locality Principle For Better Performance
In computer science, the principle of locality is the tendency of a processor to access the same set of memory locations over a short period. In such cases, there are optimization techniques that can be applied to improve performance. For example, memory prefetching is an example of an optimization where we prefetch subsequent memory locations before we even need to access them.
Enough with the technical details. Let us see how we can use this to improve performance.
We will look at two examples where we are iterating over a matrix, and counting how many elements are greater than zero. For simplicity, let’s assume we have an array of arrays, and the size is 5000×5000:
for (int i = 0; i < matrix.Length; i++)
{
for (int j = 0; j < matrix.Length; j++)
{
if (matrix[i][j] > 0)
{
result++;
}
}
}
for (int i = 0; i < matrix.Length; i++)
{
for (int j = 0; j < matrix.Length; j++)
{
if (matrix[j][i] > 0)
{
result++;
}
}
}
What do you think, which algorithm will perform faster?
If you guessed the first one, you are correct. Here are the benchmark results on our machine:
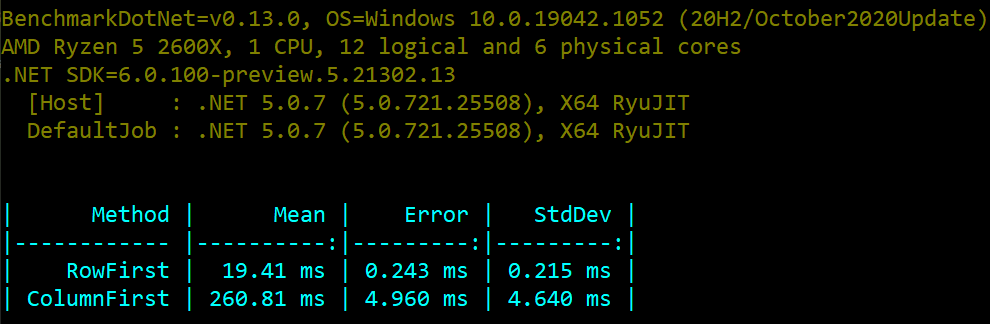
However, we should understand why this is the case. Arrays and matrices (arrays of arrays) are stored sequentially in memory. Matrices are actually stored row-first. This means that we will be accessing subsequent memory locations when we are accessing the matrix data row by row. That is how we can benefit from the memory locality principle, and gain improved performance.
Conclusion
There we go! We’ve learned 11 useful C# tips for how to improve the quality of our code and increase performance.

In case we use return new List, when I call method, how to way I can check collection is null or not.
In case of using return Enumerable.Empty, how I can check collection is null or not when I call method to use
You don’t have to check for null. You can use the Any() method to check whether the collection is empty or not.
readonly on a private field would also protect from re-initializing the list.
is goes well with upcasting and downcasting as well.
Thanks for this. Yep, that’s the case as well.
For null checks, how does the == operator can be overridden?
Hello Marko. Well for example we can have a Pearson class and override the == operator:
public static bool operator ==(Product product1, Product product2) => return product1.Equals(product2);If you, maybe inside the controller, execute this statement if (product == null), and the product is really null, this will force the == operator override to run and will fail because you can’t call the Equals method on a null instance. That’s why the is operator is more recommended way.
This is not a very common case, but the tip is good.
Thanks.
In the switch example, why not
DateTime.Now.DayOfWeek switch{not (DayOfWeek.Saturday or DayOfWeek.Sunday) => "Not Weekend",_ => "Weekend",}instead of your solution:
DateTime.Now.DayOfWeek switch{not (DayOfWeek.Saturday or DayOfWeek.Sunday) => "Not Weekend",DayOfWeek.Saturday or DayOfWeek.Sunday => "Weekend",_ => throw new ArgumentOutOfRangeException()}To prevent:
var dow = (DayOfWeek) 10;var result = dow switch{not (DayOfWeek.Saturday or DayOfWeek.Sunday) => "Not Weekend",_ => "Weekend",};// result: Not WeekendYou wouldn’t prevent this with your solution
A good observation Urs, but as Teun noted in his comment, the value that we are performing the switch expression on does not have to come from an object such as DateTime. It could come from a function argument for example. And whenever we’re working with enums, it’s best to have a default case to be on the safe side.
Good article, the pictures really help. For me, this was 70% review, but they are great tips! I personally, need to get better at not just throwing collections into
List<t>()and instead ask my self
A good rule of thumb is to think about what that collection will be used for?
Are we only returning a response to the client? Go with IReadonlyCollection.
Are we going to do something else with the collection once we create it? Probably IEnumerable is a good fit.