

In this article, we’re going to learn how to use HTML Agility Pack in C# and review some examples of its most important features.
Let’s start.
What Is HTML Agility Pack and How to Use It
HTML Agility Pack is a tool to read, write and update HTML documents. It is commonly used for web scraping, which is the process of programmatically extracting information from public websites.
To start using HTML Agility Pack, we can install it using NuGet Package Manager:
Install-Package HtmlAgilityPack
Once done, we can easily parse an HTML string:
var html = @"<!DOCTYPE html>
<html>
<body>
<h1>Learn To Code in C#</h1>
<p>Programming is really <i>easy</i>.</p>
</body>
</html>";
var dom = new HtmlDocument();
dom.LoadHtml(html);
var documentHeader = dom.DocumentNode.SelectSingleNode("//h1");
Assert.Equal("Learn To Code in C#", documentHeader.InnerHtml);
Here, we parse a string containing some basic HTML to get an HtmlDocument object.
The HtmlDocument object exposes a DocumentNode property that represents the root tag of the snippet. We use SelectSingleNode() on it to query the document model searching for the h1 tag inside the document. And, finally, we access the text content of the h1 tag through the InnerHtml property.
Parsing HTML With HTML Agility Pack
While parsing HTML documents from strings is simple, sometimes we will need to obtain our HTML from other sources.
Parsing HTML From a Local File
We can easily load HTML from files located on a local hard drive. To demonstrate that, let’s first create an HTML file and save it with the name test.html:
<!DOCTYPE html>
<html>
<body>
<h1>Learn To Code in C#</h1>
<p>Programming is really <i>easy</i>.</p>
<h2>HTML Agility Pack</h2>
<p id='second'>HTML Agility Pack is a popular web scraping tool.</p>
<p>Features:</p>
<ul>
<li>Parser</li>
<li>Selectors</li>
<li>DOM management</li>
</ul>
</body>
</html>
Then, we can instantiate a new HtmlDocument object and use its Load() method to parse the content of our HTML file:
var path = @"test.html";
var doc = new HtmlDocument();
doc.Load(path);
var htmlHeader = doc.DocumentNode.SelectSingleNode("//h2");
Assert.Equal("HTML Agility Pack", htmlHeader.InnerHtml);
Once loaded, we can query the document contents by using DocumentNode.SelectSingleNode() method. In this case, we are retrieving the second-level header text via the InnerHtml of the h2 tag in the document.
Parsing HTML From the Internet
Let’s say our goal is to get HTML from a public website. To parse content straight from a URL, we need to use an instance of the HtmlWeb class instead of HtmlDocument:
var url = @"https://code-maze.com/";
HtmlWeb web = new HtmlWeb();
var htmlDoc = web.Load(url);
var node = htmlDoc.DocumentNode.SelectSingleNode("//head/title");
Assert.Equal("Code Maze - C#, .NET and Web Development Tutorials", node.InnerHtml);
Once we parse the content by calling the Load() method of the HtmlWeb instance with the site’s URL, we can use the methods we already know to access the content. In this case, we are selecting the title tag inside the head section of the document.
Parsing HTML From a Browser Using Selenium
Often, websites use client code like javascript to render HTML elements dynamically. This may be a problem when we try to parse HTML from a remote website, causing the content to be unavailable to our program since the client code hasn’t been executed.
If we need to parse dynamically rendered HTML content we can use a browser automation tool like Selenium WebDriver. This works because we will be using an actual browser to retrieve the HTML page. A real browser like Chrome is capable of executing any client code present on the page thus generating all the dynamic content.
We can easily find resources to learn how to work with Selenium WebDriver to load a remote website. Once done, we can use the content loaded in the driver’s PageSource property:
var options = new ChromeOptions();
options.AddArguments("headless");
using (var driver = new ChromeDriver(options))
{
driver.Navigate().GoToUrl("https://code-maze.com/");
var doc = new HtmlDocument();
doc.LoadHtml(driver.PageSource);
var node = doc.DocumentNode.SelectSingleNode("//head/title");
Assert.Equal("Code Maze - C#, .NET and Web Development Tutorials", node.InnerHtml);
}
Structure of HtmlDocument
Inside a HtmlDocument instance, there’s a tree of HtmlNode elements with a single root node. The root node can be accessed through the DocumentNode property.
Each node has a Name property that will match the HTML tag that represents, like body, or h2. On the other hand, elements that are not HTML tags also have nodes whose names will start with a #. Examples of this are #document, #comment or #text:
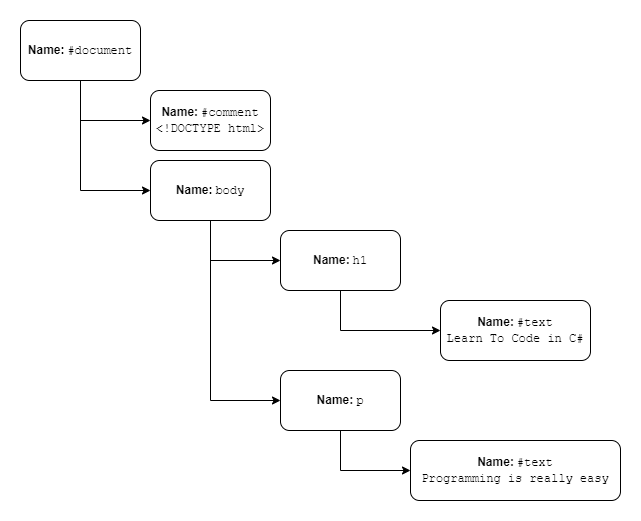
Each HtmlNode exposes the SelectSingleNode() and SelectNodes() methods to query the entire tree using XPath expressions.
SelectSingleNode() will return the first HtmlNode that matches the XPath expression along with all its descendants, while if there are no matching nodes it will return null.
SelectNodes() will return a HtmlNodeCollection object containing all nodes that match the XPath expression with its descendants.
We will often use HtmlNode properties InnerHtml, InnerText, and OuterHtml to access the node’s content.
Finally, we can access neighboring nodes with the ChildNodes, FirstChild, and ParentNode properties among others.
Using Selectors
Putting all this into practice, we can select all nodes of a specific name regardless of their position in the document tree using //:
var doc = new HtmlDocument();
doc.Load("test.html");
var nodes = doc.DocumentNode.SelectNodes("//li");
Assert.Equal("Parser", nodes[0].InnerHtml);
Assert.Equal("Selectors", nodes[1].InnerHtml);
Assert.Equal("DOM Management", nodes[2].InnerHtml);
Here, we select all the li elements in the HTML file we used in a previous example without having to specify the exact path to the elements.
Alternatively, we can use an expression to select a node by explicitly defining its position in the hierarchy using /:
var node = doc.DocumentNode.SelectSingleNode("/html/body/h2");
Assert.Equal("HTML Agility Pack", node.InnerHtml);
To select nodes relative to the current node we can use the dot (.) expression:
var body = dom.DocumentNode.SelectSingleNode("/html/body");
var listItems = body.SelectNodes("./ul/li");
Assert.Equal(3, listItems.Count);
Attribute Selectors
We can also select nodes based on their attributes like class or even id. This is done using square bracket syntax:
var node = dom.DocumentNode.SelectSingleNode("//p[@id='second']");
Assert.Equal("HTML Agility Pack is a popular web scraping tool.", node.InnerHtml);
Collections
XPath expressions can select specific items in a collection by its zero-based index or using functions like first() or last():
var secondParagraph = dom.DocumentNode.SelectSingleNode("//p[1]");
var lastParagraph = dom.DocumentNode.SelectSingleNode("//p[last()]");
Assert.Equal("Programming is really <i>easy</i>.", secondParagraph.InnerHtml);
Assert.Equal("Features:", lastParagraph.InnerHtml);
HTML Manipulation
Once we have an HtmlDocument object, we can change the structure of the underlying HTML using a collection of methods that work with document nodes. We can manipulate a document by adding and removing nodes as well as changing their content or even their attributes:
var dom = new HtmlDocument();
dom.Load("test.html");
var list = dom.DocumentNode.SelectSingleNode("//ul");
list.ChildNodes.Add(HtmlNode.CreateNode("<li>Added dynamically</li>"));
Assert.Equal(@"<ul>
<li>Parser</li>
<li>Selectors</li>
<li>DOM management</li>
<li>Added dynamically</li></ul>", list.OuterHtml);
Here we select a node in our HtmlDocument corresponding to the unordered list ul that originally contains three list items. Then, we add a newly created HtmlNode to the ChildNodes collection property of the selected node. Once done, we can inspect the OuterHtml property of the ul node and see how the new list item node has been added to the document.
Similarly, we can remove HTML nodes from a document:
var list = dom.DocumentNode.SelectSingleNode("//ul");
list.RemoveChild(list.SelectNodes("li").First());
Assert.Equal(@"<ul>
<li>Selectors</li>
<li>DOM management</li>
</ul>", list.OuterHtml);
In this case, starting from the same unordered list, we remove the first list item by calling the RemoveChild() method in the previously selected HtmlNode.
Likewise, we can alter existing nodes using properties exposes by the HtmlNode object:
var list = dom.DocumentNode.SelectSingleNode("//ul");
foreach (var node in list.ChildNodes.Where(x => x.Name == "li"))
{
node.FirstChild.InnerHtml = "List Item Text";
node.Attributes.Append("class", "list-item");
}
Assert.Equal(@"<ul>
<li class=""list-item"">List Item Text</li>
<li class=""list-item"">List Item Text</li>
<li class=""list-item"">List Item Text</li>
</ul>", list.OuterHtml);
Starting with the same unordered list, we replace the inner text in each one of the items in the list and append a class attribute using Attributes.Append().
Writing Out HTML
Often, we need to write HTML to a file after working with it. We can use the Save() method of the HtmlDocument class to do it. This method will save all the nodes in the document to a file including all the changes we may have done using the manipulation API:
var dom = new HtmlDocument();
dom.Load("test.html");
using var textWriter = File.CreateText("test_out.html");
dom.Save(textWriter);
Equally important is writing out only part of a document, usually the nodes under a specific known node. The HtmlNode class exposes the WriteTo() method that writes the current node along with all its descendants and the WriteContentTo() method that will output only its children:
using (var textWriter = File.CreateText("list.html"))
{
list.WriteTo(textWriter);
}
using (var textWriter = File.CreateText("items_only.html"))
{
list.WriteContentTo(textWriter);
}
Assert.Equal(
@"<ul>
<li>Parser</li>
<li>Selectors</li>
<li>DOM management</li>
</ul>", File.ReadAllText("list.html"));
Assert.Equal(
@"
<li>Parser</li>
<li>Selectors</li>
<li>DOM management</li>
", File.ReadAllText("items_only.html"));
Traversing the DOM
There are several properties and methods that allow us to conveniently navigate the tree of nodes that make the document.
HtmlNode‘s properties ParentNode, ChildNodes, NextSibling, and others let us access neighboring nodes in the document’s hierarchy. We can use these properties to traverse the node tree one node at a time. To optimally traverse the entire document, it may be a good idea to use recursion:
var toc = new List<HtmlNode>();
var headerTags = new string[] { "h1", "h2", "h3", "h4", "h5", "h6" };
void VisitNodesRecursively(HtmlNode node)
{
if (headerTags.Contains(node.Name))
toc.Add(node);
foreach(var child in node.ChildNodes)
VisitNodesRecursively(child);
}
VisitNodesRecursively(dom.DocumentNode);
// extracted nodes:
// h1 -> Learn To Code in C#
// h2 --> HTML Agility Pack
Here, we traverse all nodes in document order and save all the headers we find along the way in the toc collection to build a table of contents for the document. We use the ChildNodes property to recursively process all nodes.
On the other hand, methods like Descendants(), DescendantsAndSelf(), Ancestors(), and AncestorsAndSelf() return a flat list of nodes relative to the node we call the method on:
var groups = dom.DocumentNode.DescendantsAndSelf()
.Where(n => !n.Name.StartsWith("#"))
.GroupBy(n => n.Name);
foreach (var group in groups)
Console.WriteLine($"Tag '{group.Key}' found {group.Count()} times.");
Here, we get all the descendants of the root node and group them by tag name. Finally, we count the occurrences of each tag used in the document. If we apply this to the example HTML that we’ve used before, the output should look like this:
Tag 'html' found 1 times. Tag 'body' found 1 times. Tag 'h1' found 1 times. Tag 'p' found 3 times. Tag 'i' found 1 times. Tag 'h2' found 1 times. Tag 'ul' found 1 times. Tag 'li' found 3 times.
Third-Party Libraries
There are some packages that, despite being external to HTML Agility PPack work on top of it to provide additional features.
Hazz adds W3C-style CSS selectors as an alternative to the XPath syntax that comes bundled with HTML Agility Pack. These are JQuery-style selectors that we may like or know better than XPath.
ScrapySharp and DotnetSpider are higher-level web scraping frameworks that use HTML Agility Pack as their core HTML parsing engine.
Conclusion
In this article, we’ve learned what HTML Agility Pack is and how to work with it. We’ve also learned how to parse HTML from various sources and how to correctly parse websites that use client code to render dynamic content.
Then, we talked about the structure of an HTML document, how to use selectors to query it, and how to read and manipulate the elements in an HTML document.
Finally, we’ve seen some examples of how to traverse the entire document tree and learned about third-party libraries that work with HTML Agility Pack.
