

The basic idea behind the Dependency Inversion Principle is that we should create the higher-level modules with its complex logic in such a way to be reusable and unaffected by any change from the lower-level modules in our application. To achieve this kind of behavior in our apps, we introduce abstraction which decouples higher from lower-level modules.
Having this idea in mind the Dependency Inversion Principle states that
- High-level modules should not depend on low-level modules, both should depend on abstractions.
- Abstractions should not depend on details. Details should depend on abstractions.
We are going to make all of this easier to understand with an example and additional explanations.
To download the source code for this project, check out the Dependency Inversion Principle Project Source Code.
To read about other SOLID principles, check out our SOLID Principles page.
What are the High-Level and Low-Level Modules
The high-level modules describe those operations in our application that have more abstract nature and contain more complex logic. These modules orchestrate low-level modules in our application.
The low-level modules contain more specific individual components focusing on details and smaller parts of the application. These modules are used inside the high-level modules in our app.
What we need to understand when talking about DIP and these modules is that both, the high-level and low-level modules, depend on abstractions. We can find different opinions about if the DIP inverts dependency between high and low-level modules or not. Some agree with the first opinion and others prefer the second. But the common ground is that the DIP creates a decoupled structure between high and low-level modules by introducing abstraction between them.
Dependency Injection is one way of implementing the Dependency Inversion Principle.
Example Which Violates DIP
Let’s start by creating two enumerations and one model class:
public enum Gender
{
Male,
Female
}
public enum Position
{
Administrator,
Manager,
Executive
}
public class Employee
{
public string Name { get; set; }
public Gender Gender { get; set; }
public Position Position { get; set; }
}
To continue, we are going to create one low-level class which keeps (in a simplified way) track of our employees:
public class EmployeeManager
{
private readonly List<Employee> _employees;
public EmployeeManager()
{
_employees = new List<Employee>();
}
public void AddEmployee(Employee employee)
{
_employees.Add(employee);
}
}
Furthermore, we are going to create a higher-level class to perform some kind of statistical analysis on our employees:
public class EmployeeStatistics
{
private readonly EmployeeManager _empManager;
public EmployeeStatistics(EmployeeManager empManager)
{
_empManager = empManager;
}
public int CountFemaleManagers()
{
//logic goes here
}
}
With this kind of structure in our EmployeeManager class, we can’t make use of the _employess list in the EmployeeStatistics class, so the obvious solution would be to expose that private list:
public class EmployeeManager
{
private readonly List<Employee> _employees;
public EmployeeManager()
{
_employees = new List<Employee>();
}
public void AddEmployee(Employee employee)
{
_employees.Add(employee);
}
public List<Employee> Employees => _employees;
}
Now, we can complete the Count method logic:
public class EmployeeStatistics
{
private readonly EmployeeManager _empManager;
public EmployeeStatistics(EmployeeManager empManager)
{
_empManager = empManager;
}
public int CountFemaleManagers () =>
_empManager.Employees.Count(emp => emp.Gender == Gender.Female && emp.Position == Position.Manager);
}
Even though this will work just fine, this is not what we consider a good code and it violates the DIP.
How is that?
Well, first of all, our EmployeeStatistics class has a strong relation (coupled) to the EmployeeManager class and we can’t send any other object in the EmployeeStatistics constructor except the EmployeeManager object. The second problem is that we are using the public property from the low-level class inside the high-level class. By doing so, our low-level class can’t change its way of keeping track of employees. If we want to change its behavior to use a dictionary instead of a list, we need to change the EmployeeStatistics class behavior for sure. And that’s something we want to avoid if possible.
Making Our Code Better by implementing the Dependency Inversion Principle
What we want is to decouple our two classes so the both of them depend on abstraction.
So, the first thing we need to do is to create the IEmployeeSearchable interface:
public interface IEmployeeSearchable
{
IEnumerable<Employee> GetEmployeesByGenderAndPosition(Gender gender, Position position);
}
Then, let’s modify the EmployeeManager class:
public class EmployeeManager: IEmployeeSearchable
{
private readonly List<Employee> _employees;
public EmployeeManager()
{
_employees = new List<Employee>();
}
public void AddEmployee(Employee employee)
{
_employees.Add(employee);
}
public IEnumerable<Employee> GetEmployeesByGenderAndPosition(Gender gender, Position position)
=> _employees.Where(emp => emp.Gender == gender && emp.Position == position);
}
Finally, we can modify the EmployeeStatistics class:
public class EmployeeStatistics
{
private readonly IEmployeeSearchable _emp;
public EmployeeStatistics(IEmployeeSearchable emp)
{
_emp = emp;
}
public int CountFemaleManagers() =>
_emp.GetEmployeesByGenderAndPosition(Gender.Female, Position.Manager).Count();
}
This looks much better now and it’s implemented by DIP rules. Now, our EmployeeStatistics class is not dependent on the lower-level class and the EmployeeManager class can change its behavior about storing employees as well.
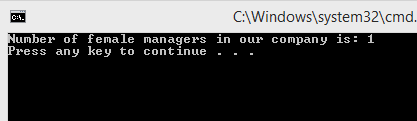
Finally, we can check the result by modifying Program.cs class:
class Program
{
static void Main(string[] args)
{
var empManager = new EmployeeManager();
empManager.AddEmployee(new Employee { Name = "Leen", Gender = Gender.Female, Position = Position.Manager });
empManager.AddEmployee(new Employee { Name = "Mike", Gender = Gender.Male, Position = Position.Administrator });
var stats = new EmployeeStatistics(empManager);
Console.WriteLine($"Number of female managers in our company is: {stats.CountFemaleManagers()}");
}
}
Benefits of Implementing the Dependency Inversion Principle
Reducing the number of dependencies among modules is an important part of the process of creating an application. This is something that we get if we implement DIP correctly. Our classes are not tightly coupled with the lower-tier objects and we can easily reuse the logic from the high-tier modules.
So, the main reason why DIP is so important is the modularity and reusability of the application modules.
It is also important to mention that changing already implemented modules is risky. By depending on abstraction and not on a concrete implementation, we can reduce that risk by not having to change high-level modules in our project.
Finally, DIP when applied correctly gives us the flexibility and stability at the level of the entire architecture of our application. Our application will be able to evolve more securely and become stable and robust.
Conclusion
So to sum up, the Dependency Inversion Principle is the last part of the SOLID principles which introduce an abstraction between high and low-level components inside our project to remove dependencies between them.
If someone asks: „Should I put an effort to implement the DIP into my code?“, our answer would be: „Yes you should“. Loosely coupled code and reusable components should be our goal and responsibility when developing software applications.

Thanks for the best Example
There are only two genders
Thanks for coming out
Thanks for the helpful example!