

Working with collections can be tricky, we all made that rookie mistake when we edited elements of a list while iterating on it. Now, we might not fall into this anymore, but there are cases where we want to ensure that our collections will remain unchanged. C# has a bunch of Immutable Collections that come in hand in these cases.
In this article, we’re going to explore how they work, how efficient they are, and when to use them.
Let’s start.
Defining Immutability
An immutable object is an object that we can’t change after we instantiate it. In C#, for example, we know that strings are immutable. Once we create a string we cannot change it, any modification done to a string actually results in creating a new one.
There are many reasons why we would choose to make our state immutable. One is code readability and maintenance.
Immutability prevents side effects, we consider a method to have no side effects when it doesn’t change any global variables or shared state. These methods are very easy to understand and debug.
Another reason is thread safety, by making our state variables immutable we guarantee that no two threads can change it at the same time.
Just like strings, manipulating immutable objects actually create new ones. Of course, this can be expensive in terms of time and memory which makes our operations inefficient. However, immutable collections achieve full immutability functionalities with good performance.
So, let’s explore them.
Different Immutable Collections in C#
An immutable collection is one whose structure never changes once created. They are designed to achieve full immutability while exposing APIs that allow all operations supported by regular collections, even mutation. Mutating an immutable collection doesn’t result in a change to it, but returns a new immutable collection with the updated state.
Let’s take an example to demonstrate this:
var initialList = ImmutableList.Create<int>(); var updatedList = initialList.Add(1);
Just like a regular list, ImmutableList has an Add method, but instead of adding the element to the initial list, it creates a new one with the added element. This goes for almost all methods. These Immutable Collections smartly provide these functionalities very efficiently, achieving time complexities that are close to regular collections.
Immutable collections are built-in types in .NET Core and .NET 5+, and are available for .NET Framework 4.5 as a Nuget package “System.Collections.Immutable“.
Enough theory, let’s see these collections in action.
Immutable Stack
Let’s start with ImmutableStack<T>. Unlike the regular stack, ImmutableStack doesn’t expose public constructors, so in order to create an instance we have to call one of its factory methods:
public static ImmutableStack<T> Create<T>(); public static ImmutableStack<T> Create<T>(T item); public static ImmutableStack<T> Create<T>(params T[] items); public static ImmutableStack<T> CreateRange<T>(IEnumerable<T> items);
The first method creates an empty stack. The second one creates a stack with one element. The third and fourth factory methods create a stack and push a range of elements to it. So creating an ImmutableStack is different from the regular one, but manipulating it is pretty much the same. ImmutableStack<T> exposes the two stack methods: Push and Pop. However, these methods don’t change the stack but return a new altered one:
var stack1 = ImmutableStack.Create<int>(); var stack2 = stack1.Push(1); var stack3 = stack2.Push(2); Assert.Equal(1, stack2.Peek()); var stack4 = stack3.Push(4); var stack5 = stack4.Pop(); Assert.Equal(4, stack4.Peek()); Assert.Equal(2, stack5.Peek());
After pushing 2 to stack2, we notice that it still has one element in it 1. Also, when we pop from stack4, it stays the same. This might insinuate that the elements are being copied at each operation, creating a whole new data structure. But this isn’t what’s happening under the hood.
Let’s explore these operations:
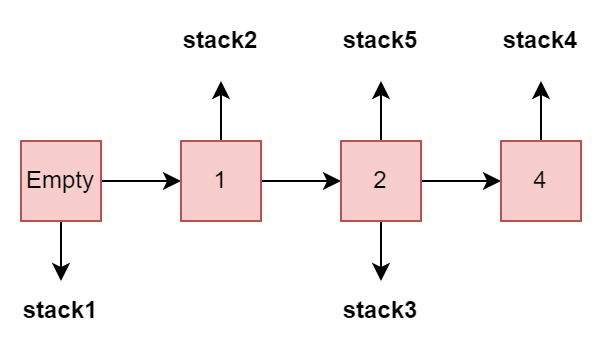
So first we have an empty stack, pointed to by stack1. After the first push operation, we add the element to the stack and have stack2 referencing the part of the stack that ends with 1. The same thing happens at the next two pushes. When we pop from stack4, we get stack5 referencing the stack that ends with 2.
So as we notice, this is almost equal in performance to a regular stack, with zero side effects.
Immutable List
The stack is a very simple data structure, we can only pop and push. The list, however, has more functionalities. So, let’s play around a little bit with ImmutableList<T>:
var list1 = ImmutableList.Create<int>(); Assert.Empty(list1); var list2 = list1.Add(1); Assert.Single(list2); var list3 = list2.Add(2); Assert.Equal(2, list3.Count); var list4 = list3.Add(3); Assert.Equal(3, list4.Count); var list5 = list4.Replace(2, 4); Assert.Equal(3, list5.Count);
Similarly, we are able to manipulate the list just like a regular one, but each operation results in a separate immutable list. In order to achieve all functionalities of the regular list while maintaining reasonable performance, ImmutableList<T> uses a binary tree as a data structure. In-order Depth First traversal of the tree corresponds to traversing the list from index 0 to the end of the list.
Now, let’s walk through the above operations:
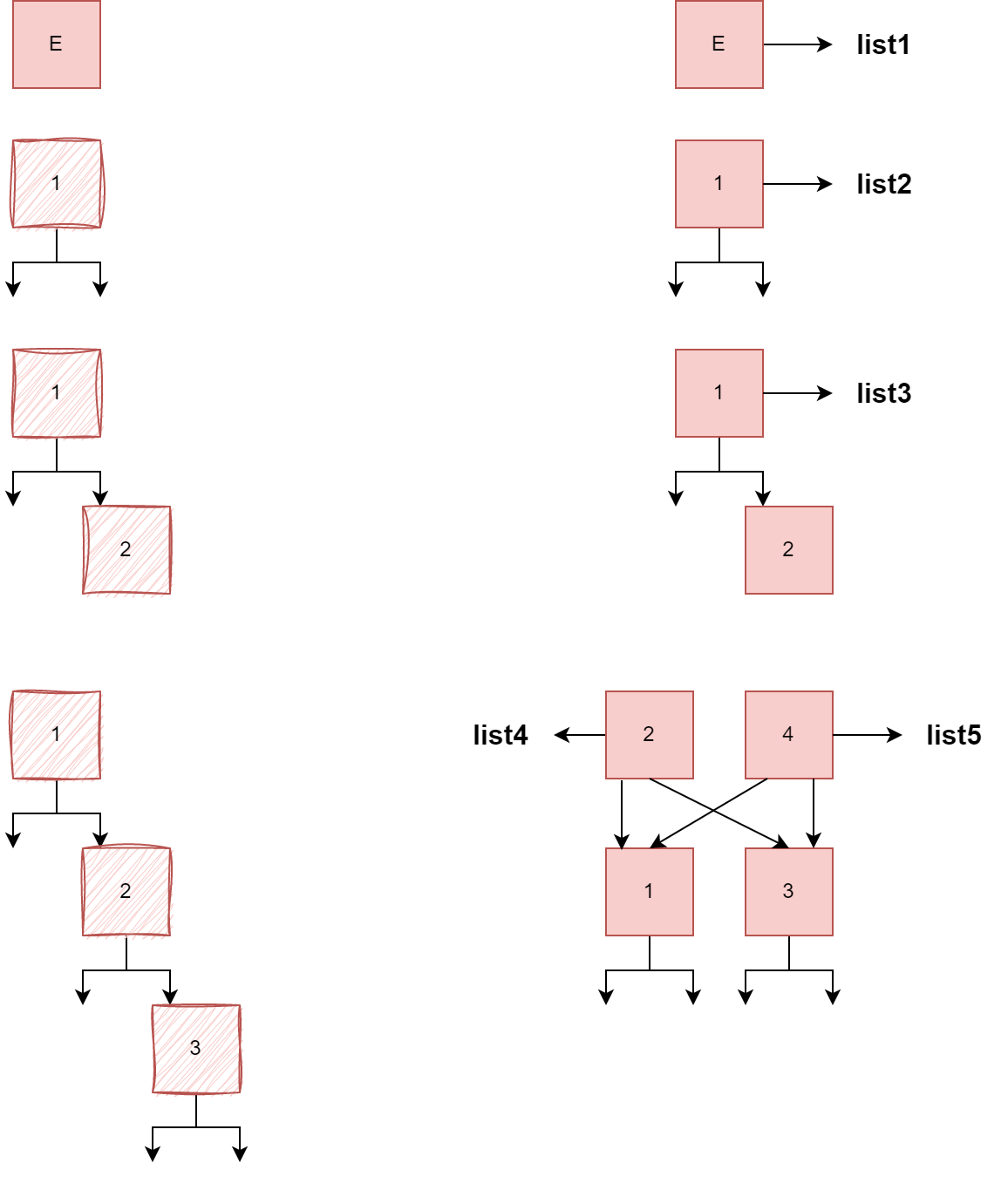
In this image, the left part represents an intermediate state for each operation, and the right is the final. On the left part, the collection is temporarily mutable, but not publicly accessible. On the right part, the structure is immutable forever.
First, we have list1 referencing an empty list, which is an empty singleton node. Then we have list2, referencing a tree of one node. To add a new element, we can just create a new node and add it as the right child to the first node. However, the first node is immutable and so are its pointers. This is why a whole new tree is created. We then add a new number. Similarly, we copy the whole tree and add the new node as the right child.
Now, the tree is out of balance; the difference between the height of the right and that of the left side is greater than 2. But since it’s still temporarily mutable, we can mutate the structure to have the middle element as the root, and list4 references it.
In the last operation, we replace the middle node. We achieve this by creating a new node and creating pointers from it to the existing child nodes. This is how any mutation operation is optimized. This structure guarantees a time complexity of O(log N) for all operations: insertion, deletion, and retrieval.
Immutable Array
Let’s see how we can utilize ImmutableArray<T>:
var immutableArray = ImmutableArray.Create<int>(1, 2, 3, 4); var firstElement = immutableArray[0]; Assert.Equal(1, firstElement); var lastElementIndex = immutableArray.BinarySearch(4); Assert.Equal(3, lastElementIndex);
We create an immutable array, and we are able to access its elements by index or by calling BinarySearch(). The regular array provides some immutability, that is its fixed length. ImmutablArray furtherly prevents the change of its elements.
Let’s try it:
immutableArray[0] = 5;
We see a red squiggly line that on hovering says: Property or indexer ‘property’ cannot be assigned to — it is read only.
Unlike Lists,ImmutableArray<T> uses an actual array to achieve functionality. For each mutating operation, a whole new copy of the array is created, including the changes. While the writing operations are O(N) operations, retrieval using the index is O(1), which makes this reasonable to use in some cases. Iteration on ImmutableArray<T> is a little bit faster than ImmutablList<T>, because elements are stored consecutively in memory. Also, ImmutableList<T> takes up more storage to allocate the pointers.
As a rule of thumb, we should generally use ImmutableArray<T> if we read from the collection more frequently than we write to it.
Immutable Dictionary
Let’s explore ImmutableDictionary<TKey, TValue>:
var dict1 = ImmutableDictionary.Create<int, char>();
var dict2 = dict1.Add(1, 'a');
Assert.Single(dict2);
Assert.True(dict2.ContainsKey(1));
Assert.Equal('a', dict2[1]);
var dict3 = dict2.Add(2, 'b');
Assert.Equal(2, dict3.Count);
var dict4 = dict3.Remove(2);
Assert.Single(dict4);
Similar to the regular dictionary, we can Add() and Remove() elements from the immutable dictionary. The difference is these two methods now return a whole new dictionary. We also have ContainsKey() to check if a key exists, which is actually essential because although we can call TryAdd(), it’s not useful here. This method is part of the IDictionary interface, which is implemented byImmutableDictionary. However, because this is a mutating method, ImmutableDictionary implements it to throw a NotSupportedException.
We notice this behavior with other immutable collections as well. In order to be more usable in existing code bases, Immutable Collections implement some common interfaces like IList, ICollection, IEnumerable, and IDictionary. However, their implementation of mutating methods of these interfaces is throwing NotSupportedException.
As we would imagine the implementation of ImmutableDictionary<TKey, TValue> is rather complex. The operations take much more space and time than other immutable collections, so we must measure performance before we decide to go with it.
Immutable SortedSet
The SortedSet is an interesting collection, their elements have two main characteristics: they are sorted, and they don’t contain any duplicates. ImmutableSortedSet<T> is the immutable thread-safe version of SortedSet<T>.
Let’s see how it operates:
var sortedSet1 = ImmutableSortedSet<int>.Empty; var sortedSet2 = sortedSet1.Add(5); var sortedSet3 = sortedSet2.Add(1); Assert.Equal(1, sortedSet3[0]); Assert.Equal(5, sortedSet3[1]); var sortedSet4 = sortedSet2.Add(1); Assert.Equal(2, sortedSet4.Count); var sortedSet5 = sortedSet4.Remove(1); Assert.Single(sortedSet5);
We are now familiar with the process. First, we create an empty set, and for each Add() operation we get a new set. The elements are sorted regardless of their addition precedence, and no duplicates are allowed. We can also Remove() elements from the set, which results in a new set with the updated state.
When to Use Immutable Collections
The main advantage of immutability is that it makes it much easier to understand how the code operates, and get a clear idea about states. It allows us to write elegant code that has no side effects and is thread-safe.
Using Immutable Collections is also a good choice when we have a collection that we process as we insert into it. Let’s say we have a speech-to-text service that transcribes media in real-time. The processing is done in the background on a multicore host while the media is running. If we’re using some regular collection to store the buffer, we’re definitely going to face race conditions. Instead, each background process can only access a snapshot of the buffer.
Let’s actually explore some options for designing an API that achieves that:
public void Transcribe(List<byte> buffer);
We use a list to store audio data as it plays. Now, there are two problems with this method. We cannot guarantee that the method will not modify the buffer while processing. This risks the loss of the original state. Another issue is we cannot tell that this method is thread-safe, as we might have multiple threads accessing the same list, again leading to state loss and inconsistency.
Of course, we can use Immutable Collections to improve this method signature:
public void Transcribe(ImmutableList<byte> snapshot);
This method expects a snapshot of the buffer, an immutable structure that we don’t care about its state before the method. We also can be sure that no two threads will be sharing this collection, so it is thread-safe.
Summary
In this article, we defined immutability and explored the Immutable Collections types of C#. We have seen how they operate under the hood, how they achieve all regular operations, and when to decide to use them.
