

In this article, we will learn what is an aggregate in Domain-Driven Design. We will get to know which are the main design principles behind it. We will, also, design and implement a simple use case using these principles and learn how to organize business logic and data access.
Let’s start.
What’s an Aggregate in Domain-Driven Design?
In Domain-Driven Design we organize our business logic around domain entities. Domain entities are classes that represent well-known business concepts and keep together application data and business logic or behaviors.
For example, a hypothetical Product domain entity will hold all the properties of a retail product like Name, Category, or Price while also containing all the related business behaviors like ApplyDiscount() or IncreaseStock().
In turn, an aggregate is a set of domain entities that are meant to be managed as a single one. The canonical example of an aggregate is an Order entity and the OrderItems inside it, forming an aggregate that contains both entities.
Invariant Business Rules
In Domain-Driven Design, invariant business rules (or simply invariants) are rules that define the core business logic and constraints that must hold at all times. These rules represent essential business requirements.
Examples of invariant business rules might include things like:
- A bank account balance cannot be negative
- A customer’s date of birth must be before the current date
- A product cannot be sold for less than its cost
Rather than implementation details or technical constraints, invariant business rules are high-level, domain-specific rules that govern the behavior of the system as a whole.
How to Design an Aggregate: The Aggregate Root
An aggregate defines a boundary that separates the entities inside it from the rest of the application. The entity representing the central business concept in the aggregate will act as the aggregate root.
The aggregate root will be the main entity of the group. This entity will expose business behaviors and enforce the business invariant rules related to the entities that are internal to the aggregate.
The outside world will interact with the aggregate only through its root. In this way, we will always be able to enforce business invariants and maintain a consistent internal state. We must avoid dependencies between entities inside the aggregate and any kind of outside object and vice-versa.
When it comes to data access, aggregates become the basic unit for data storage and retrieval. We will typically have a single repository per aggregate. The repository’s interface will be based on the aggregate root entity rather than the internal ones.
The Anemic Domain Model Anti-Pattern
Let’s consider a scenario where we already implemented our online shop order management software using a domain-driven approach.
Unfortunately, we didn’t apply aggregate design principles upfront. In that case, we will probably end up with entity classes that are just classes that match our business concepts with all public properties.
To start with, we would have defined an enumeration type to represent the different possible states an order can be in:
public enum OrderStatus { PendingPayment, ReadyForShipping, InTransit }
Then, another class for the information related to each of the products inside the order:
public class OrderItem
{
public long OrderItemId { get; set; }
public Order Order { get; set; }
public string ItemName { get; set; }
public int Quantity { get; set; }
public decimal UnitPrice { get; set; }
}
And finally, a class to represent the order itself:
public class Order
{
public long OrderId { get; set; }
public DateTime CreationDate { get; set; }
public decimal PaidAmount { get; set; }
public OrderStatus Status { get; set; }
public ICollection<OrderItem> Items { get; set; } = new List<OrderItem>();
}
Although these objects model the data structures and the relationships in our domain correctly, they do not contain any business logic. On top of that, they do nothing to enforce our business invariants since they expose all the properties and their default constructors.
This allows any component to create orders in ways that may not comply with all our business rules. Furthermore, anyone can update perfectly valid orders in ways that would make them invalid.
Often, these half-backed domain entities come hand-in-hand with a layer of so-called domain services. This services, usually implement all the calculations and take care of storage concerns:
// Anemic domain model.
public interface IOrdersService
{
Task AddAmountDiscountAsync(Order order, string description, decimal amount);
Task<OrderItem> AddOrderItemAsync(Order order, string name, decimal price, int units);
Task AddPercentageDiscountAsync(Order order, string description, decimal percentage);
Task CancelOrderAsync(Order order);
Task<Order> CreateOrderAsync();
Task SendToCustomerAsync(Order order);
}
Such implementations tend to rely on specific storage technologies, like EntityFramework, and directly use domain entities as models for persistence.
If our domain classes look like this, most probably our design suffers from what is called the anemic domain model anti-pattern.
The Order Aggregate
Let’s take steps to improve our domain model using aggregate design principles. First and foremost, we decide that the Order entity will be our aggregate root. The Order class will be responsible to manage other entities inside the same aggregate and to keep the internal state consistent.
Refactoring the Order Class
First, to prevent code outside the aggregate from changing internal data arbitrarily, we must make our property setters private:
public class Order
{
internal List<OrderItem> _items = new();
public long OrderId { get; private set; }
public DateTime CreationDate { get; private set; }
public decimal PaidAmount { get; private set; }
public DateTime? ShippingDate { get; private set; }
public OrderStatus Status { get; private set; }
public Order()
{
Status = OrderStatus.PaymentPending;
CreationDate = DateTime.Now;
}
public IReadOnlyCollection<OrderItem> Items => new ReadOnlyCollection<OrderItem>(_items);
}
Let’s keep our class constructor public since we want it to be the creation point for the entire aggregate. However, we will make sure that this constructor initializes the Order class in a way that is consistent with our business rules. In this case, that means setting the OrderStatus to PaymentPending.
The next important thing to realize is that we will have a lot of business invariants related to the OrderItems collection. Our aggregate root and no one else will have to enforce them so we will make the _items collection internal while exposing a read-only version via the Items public property. In this way, we let consumers access the information while, at the same time, we keep the aggregate root as the only component able to update it.
While giving the _items field private access will protect it more against unexpected modifications from outside the aggregate. It will also prevent our data access code from easily populating the aggregate with data coming from the data storage. We will leverage here the fact that Automapper can handle internal fields just fine.
Refactoring the OrderItem Class
Now let’s apply the same principles to our OrderItem entity. As we did with the Order class, we will keep all the property setters private:
public class OrderItem
{
public long OrderItemId { get; private set; }
public string ItemName { get; private set; }
public uint Quantity { get; private set; }
public decimal UnitPrice { get; private set; }
internal OrderItem(string itemName, uint quantity, decimal unitPrice) {...}
}
Considering that the OrderItem entity is internal to our aggregate, we want to prevent instances of this entity from being created outside of it. There isn’t an easy way to enforce this behavior. However, we can make the default constructor internal so the creation of this object is at least restricted to our domain assembly.
Implementing Behaviors
Until this point, we used well-known OOP techniques to implement the data structures and relationships that define our orders aggregate. However, Domain-Driven Design is all about keeping business logic and data together so now it is time to implement our business behaviors.
There are a few business processes we need to support:
- Accept payments to an order
- Add and remove items in an order and update the quantity of an order item
- Manage order status and be able to ship an order to a customer
Payments Management
Let’s start with the Order class and implement our payment management features. First, let’s implement a read-only property to easily access the order’s total amount. Then, let’s create an AddPayment() method:
public decimal OrderTotal => _items.Sum(x => Convert.ToDecimal(x.Quantity) * x.UnitPrice);
public void AddPayment(decimal amount)
{
if (amount <= 0)
throw new InvalidOperationException("Amount must be positive.");
if (amount > OrderTotal - PaidAmount)
throw new InvalidOperationException("Payment can't exceed order total");
PaidAmount += amount;
if (PaidAmount >= OrderTotal)
Status= OrderStatus.ReadyForShipping;
}
Within AddPayment() we will check a couple of business rules: “Payment amounts can’t be negative” and one “can’t pay more than the order total”. Also, we are implementing another business-related behavior: The order becomes ready for shipping once the OrderTotal has been paid.
Order Items and Quantities
The rules related to the creation of individual OrderItem entities are something that we want to keep close to the entity itself, so let’s add an internal constructor to the OrderItem class that can enforce those rules:
private OrderItem() {}
internal OrderItem(string itemName, uint quantity, decimal unitPrice)
{
if (string.IsNullOrEmpty(itemName))
throw new ArgumentException($"'{nameof(itemName)}' cannot be null or empty.", nameof(itemName));
if (quantity == 0)
throw new ArgumentException("Quantity must be at least one.", nameof(quantity));
if (unitPrice <= 0)
throw new ArgumentException("Unit price must be above zero.", nameof(unitPrice));
ItemName = itemName;
Quantity = quantity;
UnitPrice = unitPrice;
}
Here, we implement an alternative internal constructor that takes parameters for item data, item quantity, and unit price. The constructor signature reflects a business rule: It’s not allowed to have an order item missing any of those elements.
Also, we perform a series of validations aligned to our business invariants, like, “Item must have a name” or “unit price must be above zero”. Note how we made our default parameterless constructor private. By doing this, prevent anyone from using the default constructor to skip the validations we just implemented.
Adding and withdrawing units from a specific order item is something we want to support so, in the same OrderItem entity, we will have to provide the means for it.
The Quantity property itself has a private setter to avoid anyone messing with it unexpectedly. However, we can always provide public entity methods that will better model our domain semantics enforcing business rules:
internal void AddQuantity(uint quantity)
{
this.Quantity += quantity;
}
internal void WithdrawQuantity(uint quantity)
{
if (this.Quantity - quantity <= 0)
throw new InvalidOperationException("Can't remove all units. Remove the entire item instead.");
this.Quantity -= quantity;
}
Now, in the Order entity, let’s create methods to add and remove order items. Another business rule shows up here, “The order items can’t be modified once the order has been paid”:
public void AddItem(string itemName, uint quantity, decimal unitPrice)
{
if (Status != OrderStatus.PendingPayment)
throw new InvalidOperationException("Can't modify order once payment has been done.");
_items.Add(new OrderItem(itemName, quantity, unitPrice));
}
public void RemoveItem(string itemName)
{
if (Status != OrderStatus.PendingPayment)
throw new InvalidOperationException("Can't modify order once payment has been done.");
_items.RemoveAll(x => x.ItemName == itemName);
}
Let’s also add a couple of wrapper methods for adding and withdrawing item quantity more concisely:
public void AddQuantity(string itemName, uint quantity)
=> _items.FirstOrDefault(x => x.ItemName.Equals(itemName))?.AddQuantity(quantity);
public void WithdrawQuantity(string itemName, uint quantity)
=> _items.FirstOrDefault(x => x.ItemName.Equals(itemName))?.WithdrawQuantity(quantity);
Order Shipping
Lastly, back to the Order entity, let’s implement our ShipOrder() method. This method will take the order to the InTransit state not before performing some more validations. This time we will check that the order has at least one item, is fully paid and hasn’t been shipped before:
public void ShipOrder()
{
if (_items.Sum(x => x.Quantity) <= 0)
throw new InvalidOperationException("Can´t ship an order with no items.");
if (Status == OrderStatus.PendingPayment)
throw new InvalidOperationException("Can´t ship order unpaid order.");
if (Status == OrderStatus.InTransit)
throw new InvalidOperationException("Order already shipped to customer.");
ShippingDate = DateTime.Now;
Status = OrderStatus.InTransit;
}
Putting It All Together
With these changes in place, we now have a rich domain model that encapsulates our business rules and keeps our data in a consistent state. Our code becomes more intuitive and safer since the logic embedded in the domain objects prevents them to go into illegal states:
Order order = new();
order.AddItem("Cloudsoft Women's Running Shoes", 1, 59.99M);
order.AddItem("Gildone Men's Crew T-Shirt", 3, 18.99M);
order.AddPayment(20.0M);
order.ShipOrder(); // ERROR: Can´t ship unpaid order.
Decoupling Domain Model And Persistence in Aggregate Design
In Domain-Driven Design we want our domain to remain focused on business logic. Consequently, we do not want other concerns, like data storage and persistence, to leak into it.
Data Access Abstractions as Part of the Domain
With that in mind, let’s add to our domain a repository abstraction that revolves around the aggregate concept. There will be a single repository per aggregate and its methods will use the aggregate root entity as the basic unit for data storage and retrieval:
public interface IOrdersRepository
{
Task<Order?> GetByIdAsync(long id);
Task<Order> CreateAsync(Order entity);
Task<Order> UpdateAsync(Order entity);
}
As mentioned before, the repository interface belongs to the domain and it must be in the same project or assembly as the domain entities. In contrast, repository implementation deals with persistence concerns and must reside in the data access layer: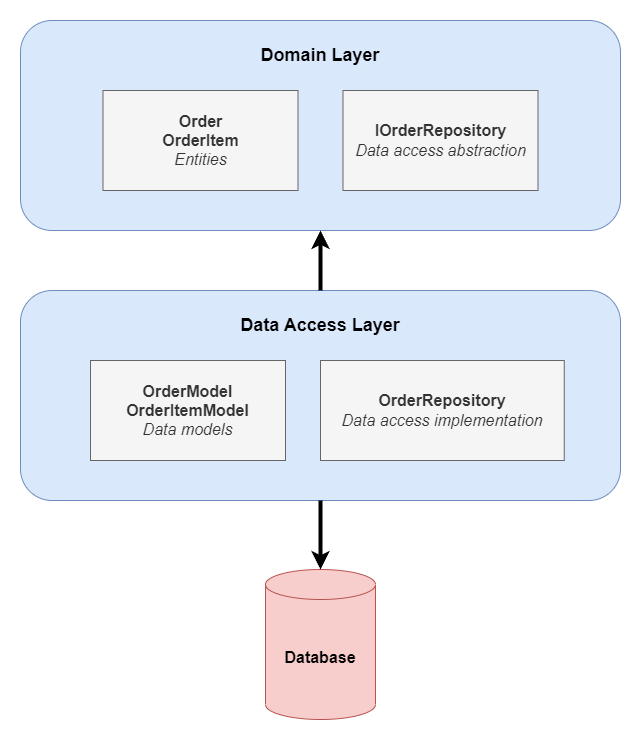
With this setup, we avoid establishing a dependency between our domain and the data access code. This helps to keep it free from data access specifics and focused on business logic.
Domain Entities vs Data Models
Consider our domain entities as they were implemented in the anemic domain model example: Seems quite straightforward to use those classes as the data models for object-relational mappers such as entity framework.
However, as we start applying domain-driven design techniques, entities become much more complex, and it gets difficult to use them for both domain modeling and data access. So, unless our use case is extremely simple, we would not use entity classes as data modeling objects.
Following this principle, let’s implement a set of data model objects which will be the ones used for database mapping. These objects can freely deal with storage-related concerns like foreign keys, indexes, etc. without polluting our domain:
public enum OrderModelStatus { PendingPayment, ReadyForShipping, InTransit }
[Table("Orders")]
public class OrderModel
{
[Key]
public long OrderId { get; set; }
public DateTime CreationDate { get; set; }
public decimal PaidAmount { get; set; }
public DateTime? ShippingDate { get; set; }
public OrderModelStatus Status { get; set; }
public ICollection<OrderItemModel> Items { get; set; } = new List<OrderItemModel>();
}
[Table("OrderItem")]
public class OrderItemModel
{
[Key]
public long OrderItemId { get; set; }
public long OrderId { get; set; }
public OrderModel? Order { get; set; }
public string? ItemName { get; set; }
public uint Quantity { get; set; }
public decimal UnitPrice { get; set; }
}
Of course, during data storage and retrieval operations, we will have to map entities to data models and vice-versa. Manually mapping object properties quickly becomes tedious and error-prone. Especially considering that the setters in our entities have restricted access. We can optionally use a mapping library like AutoMapper to help with that part.
With that in mind, let’s create an implementation for the IOrdersRepository interface in our data access layer and add the GetByIdAsync() method to it:
public class OrdersRepository : IOrdersRepository
{
private readonly OrdersDbContext _dbContext;
private readonly IMapper _mapper;
public OrdersRepository(OrdersDbContext dbContext, IMapper mapper)
{
_dbContext = dbContext;
_mapper = mapper;
}
public async Task<Order?> GetByIdAsync(long id)
{
var dataModel = await _dbContext.orders
.Include(x => x.Items)
.FirstAsync(x => x.OrderId == id);
if (dataModel is null)
return null;
var entity = _mapper.Map<OrderModel, Order>(dataModel);
return entity;
}
}
Let’s add now the implementation for the CreateAsync() method to create new orders in the database:
public async Task<Order> CreateAsync(Order entity)
{
var dataModel = _mapper.Map<Order, OrderModel>(entity);
var entry = _dbContext.Add(dataModel);
await _dbContext.SaveChangesAsync();
return _mapper.Map<OrderModel, Order>(entry.Entity);
}
And, finally, let’s add the UpdateAsync() method that will modify existing orders in the database according to changes made to our domain entities:
public async Task<Order> UpdateAsync(Order entity)
{
var dataModel = _mapper.Map<Order, OrderModel>(entity);
var attached = await _dbContext.orders
.Include(x => x.Items)
.SingleAsync(x => x.OrderId == entity.OrderId);
_dbContext.Entry(attached).State = EntityState.Detached;
foreach (var item in attached.Items.ToList())
_dbContext.Entry(item).State = EntityState.Detached;
var entry = _dbContext.Attach(dataModel);
await _dbContext.SaveChangesAsync();
return _mapper.Map<OrderModel, Order>(entry.Entity);
}
With this, we have a complete implementation of the data access repository for the Order aggregate that uses EntityFramework for persistence. The highlighted lines show code that maps data between domain entities and data models using AutoMapper.
Conclusion
In this article, we have learned what an aggregate is in Domain-Driven Design and which are the principles behind this design. We have learned about the aggregate root concept and how to use it when designing our aggregates.
After that, we defined what the anemic domain model anti-patter is, and went on to implement an Order aggregate following proper aggregate design and domain-driven practices.
Finally, we have learned how to design our data repositories around our aggregates. More importantly, we learned how to avoid coupling domain logic and persistence together.

